Introducing: grammr
The preface: Building cool stuff
I really enjoy building things. Especially in the age of LLMs, building things is easy. Building something that people are interested in is hard. Getting through the amount of AI slop that everybody is pumping out right now and building something you genuinely believe in is even harder.
I recently finished my third iteration of a pet project I’ve been working on for months. I’m not entirely certain of its value to people – it is a website where an app would likely be more appropriate, and it competes with products that have seen years of development with the work of dozens, if not hundreds of domain experts.
All of that said, in the process of building I did some pretty solid engineering work that I’d like to share. I’m mostly doing this for the love of the game, but if somebody enjoys the product or at least sees potential in it, I’d take that as well.
grammr
I recently started learning Russian for my fiancée, and it’s been challenging. Naturally, instead of actually learning the language with tools like Duolingo and Babbel, I invested dozens, if not hundreds of hours into building the perfect language learning tool to help me learn Russian. Time well invested! Enter: grammr.
What grammr does that other platforms don’t is that it gives you a highly systematic approach to learning. Russian, for example, is a “fusional language”, which means that you base forms of words are modified to convey grammatical, syntactical or semantic features. If you’ve studied Latin in school, this is something you’re familiar with in the form of conjugation and declension tables.
For example, to say “What are you doing this evening?” in Russian you’ll say “Что ты делаешь сегодня вечером?”. “ делаешь” here means “to do”, but it specifically means “you are doing”. “I do” would be “делаю”. English simply does not have this concept outside of the third person singular (“I do”, “you do”, “he/she/it does”). Well, Russian does it for every person/number permutation. This is the process of inflecting a word.

The above is the inflection table of the verb “делать”. There is no gigantic database or collection of words; instead, it is generated on the fly using the pymorphy3 Python library.
The value proposition
Duolingo gives you sentences to study, but it provides you with a very limited knowledge of why sentences are structured the way they are. I’ve attempted to rectify that: You can translate and study sentences, and when you do, you can click each word to get a detailed breakdown of each word.
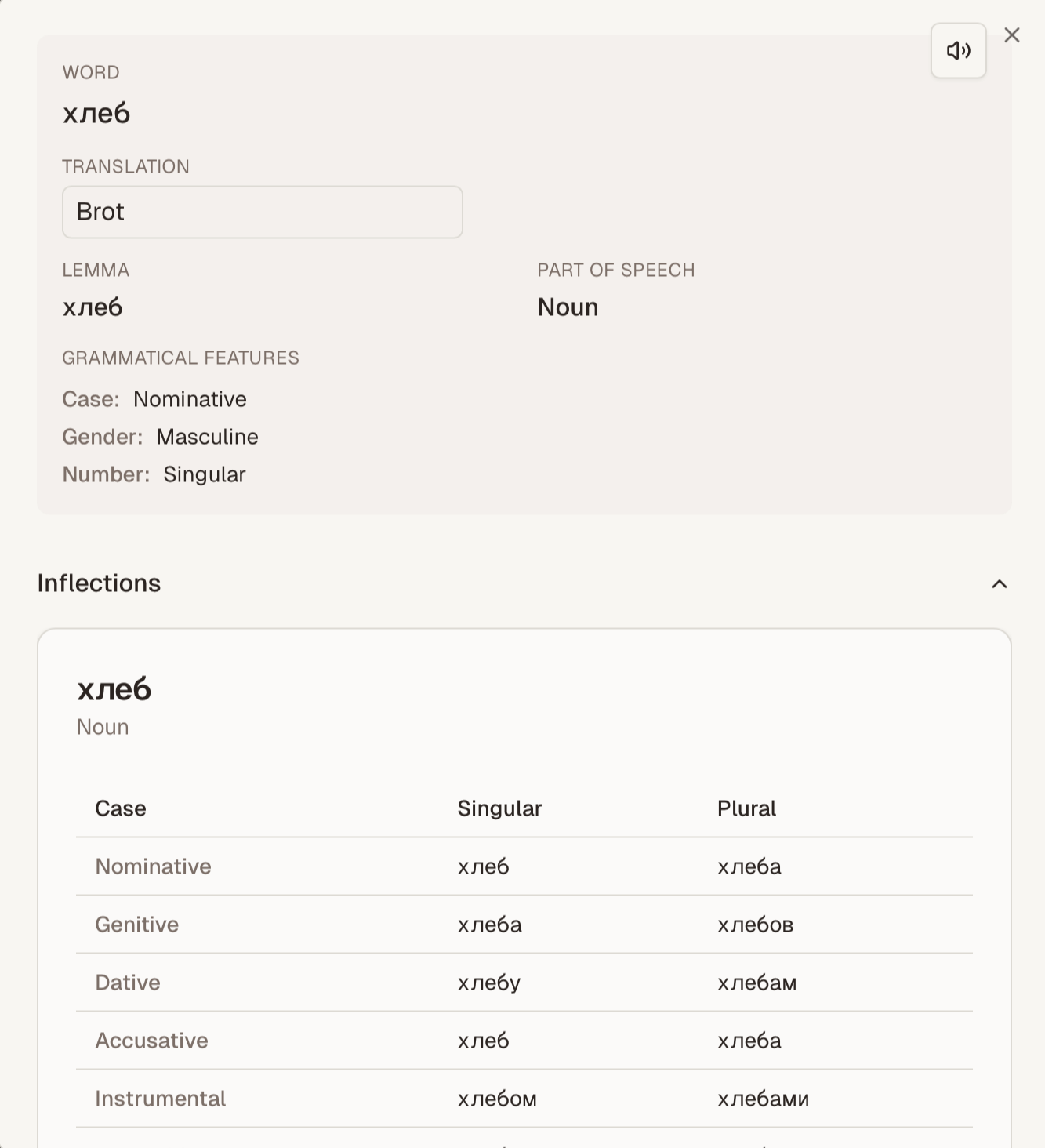
I’ve used spaCy, a popular Python-based NLP library under the hood to facilitate a deeper understanding of the underlying syntax and grammar (thus the name of the website).
You can store sentences and individual words as flashcards, which you can study using the FSRS (free spaced repetition scheduler) algorithm.
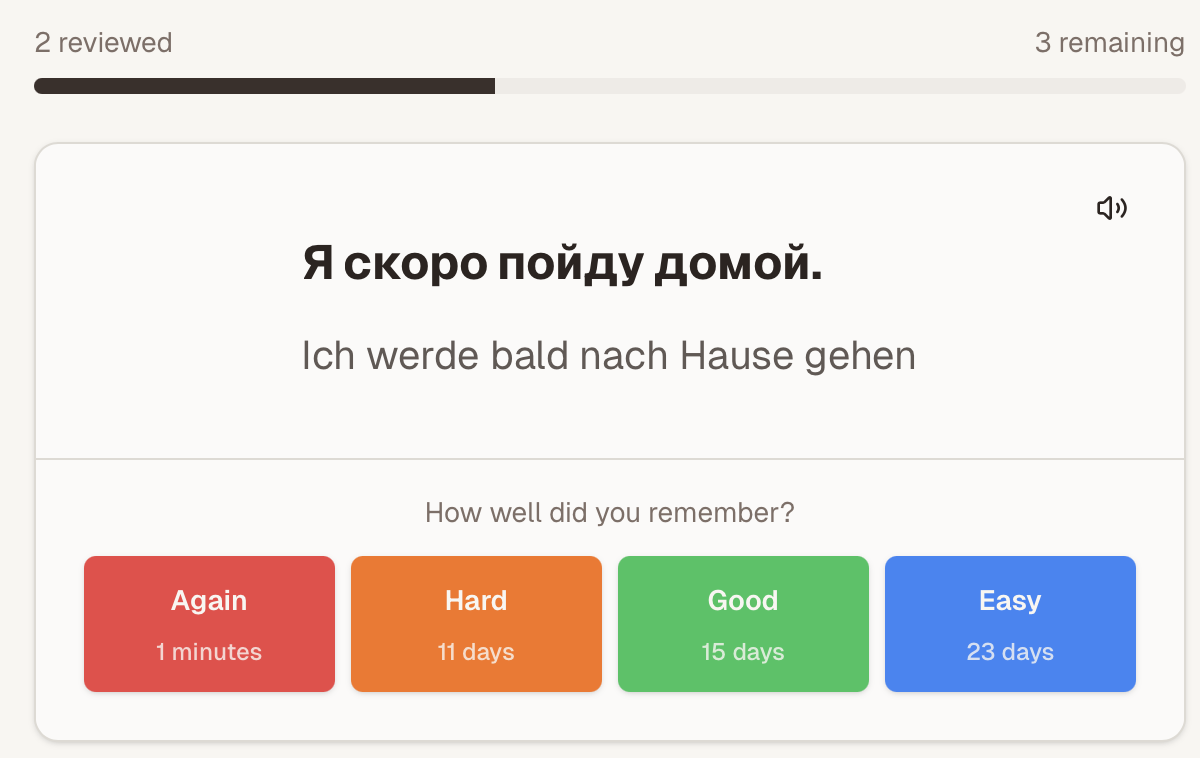
If you’re interested in language learning, it’d mean the world to me if you tried it out and provided some feedback. I’ve made it as easily accessible as possible. Check it out here: grammr.app.
Engineering
Now for the part I really enjoy. I’ll be honest with you: I’m not convinced this is a product people are going to want to use (yet). I’m hoping to maybe find a niche community, but I doubt this will ever find mainstream appeal. That being said, the engineering side of things has been really enjoyable.
Conjugation & Declension Tables
One of the first things people ask me when I show them conjugation and declension tables is: “Where do you get the data”? A comparable project to this is openrussian.dev, who kindly open-sourced their database. They sourced their inflections (i.e. conjugations & declensions) from Wiktionary and stored them in a database, which is completely valid. I took a bit of a different approach.
Instead, I sourced multiple specialized libraries that can create inflections for various languages. Specifically, there is pymorphy3 for Russian, as well as verbecc for verbs of the Romance language family. I currently maintain Italian, French, Portuguese and Spanish inflection services as those are the most commonly spoken and learned languages of this family.
I then defined a common data structure that all these map to. I’ve defined an OpenAPI Spec with the data format that all inflection services are expected to return. They use universal features, which is the most commonly used NLP standard I could identify. This allows for easy extension of the inflection services; for example, English could be added trivially using the popular inflect library. Since writing this code, I’ve also discovered the pyinflect project which might be worth looking into.
I believe this might be of interest to the NLP community, as it provides a simple, standardized and extensible REST interface for retrieving inflections for various language.
The Serverless Stack: Learning from previous iterations
This is actually the third iteration of this project. The first iteration was deployed as a Telegram bot that you could forward sentences in any language to. I soon rejected this design based on the fact that it was too limited in displaying complex information.
In the second iteration, I decided to built a core service using Java and Spring Boot, which is my professional stack and which I decided might be better at handling complex domain logic. I ran the NLP components as Flask-based webservers and orchestrated deployments in a k3s server running at home. I ended up rejecting this architecture for multiple reasons:
- Language sprawl: Domain objects had to be maintained across three tiers in three languages: The Python-based NLP services, the Java-based core service as well as the Typescript frontend. This led to a lot of duplication. I briefly looked into centralized gRPC type definitions, but decided that the effort was not worth it.
- Hosting effort: Hosting the variety of web services turned out to be a lot of effort; maintaining uptime in a fragile homelab turned out to be difficult, with large deployments regularly crashing because I had to pull various images concurrently frequently around ~1GB in size due to model weights. The namespace would consume several GBs of RAM, and maintaining a staging and production environment turned out to be extremely expensive and tedious.
- Bad design: I approached this iteration as an engineer with no product thinking. I did not scope the product properly, leading to me trying to support every usecase under the sun. I did not require users to sign in, which led to me having to hop through various loops supporting anonymous users with no language preferences, performing language detection, writing an
AnonymousUserFilterbased on ad-hoc session cookies and more things that did not actually help me identify whether or not anybody was interested in the product. Also, this was the first time I built my own frontend, my first experience with NextJS, and it was just … bad.
This iteration has been incredibly fun to work with, even as it grows. Learning from my first two failed iterations, I made a lot of correct assumptions in the beginning, leading to very solid design.
The most central part of this design is using the very standard AWS API Gateway + Lambda stack for the compute-intensive, Python-based NLP tasks, and doing everything else in NextJS, deployed on Vercel. Lambda code is dockerized, with medium-size models chosen to achieve ~300Mb images to achieve an acceptable trade-off between relatively quick cold-start times and sufficient accuracy.
Absolutely everything is managed in Terraform: The Vercel projects, its environment variables, the domains; all AWS resources, and even the Supabase project.
No CI/CD: Pragmatic DevOps
I actually have not built any CI. The most common component I deploy is the frontend, which is connected to Vercel. This gives me continuous deployment out of the box. For my Lambdas, I have build scripts to create and push images when I make changes. I use Taskfile to apply Terraform changes by running task apply:prod or task apply:dev. I firmly believe that for this stage of the project, investing the time to get a mature CI/CD set up would be overkill. My professional background is that of a DevOps engineer, so this may seem like a very unconventional choice, but I fully stand behind it. As a matter of fact, I believe this conscious choice to be a sign of my increasing maturity as an engineer, realizing that rules can sometimes be broken.
Supabase: The good, the bad, the ugly
The previous iteration used a self-hosted Postgres instance for storage and Clerk for authentication. This time around, I used Supabase to consolidate those essential features. For those who are not familiar with Supabase: It’s a managed service that combines a hosted Postgres database, authentication, Lambda-like edge functions, storage and half a dozen other services into one. And I gotta say: I love it. It’s a great product. But I would be remiss to not point out its shortcomings.
The Good: Even the free tier gives you a lot. Up to 100k users, sufficient database storage for an MVP using a t3g.nano instance, uncomplicated ways to access the database. There are various features I have not used and likely will not be using: For instance, if I were to store audio blobs, I probably would do so with S3, a Lambda and an additional API Gateway endpoint. When your product actually makes money, going all-in on Supabase may make sense, but on the limited free plan, I would rather work with the pay-as-you-go pricing that AWS offers.
The Bad: The biggest problem with Supabase on the free plan is that you do not get to separate between your staging and production databases. If you want to test a migration on staging, that affects prod as well. This makes it very difficult to safely test outside of your local environment. That said, you get to have two free project, meaning you could have a dedicated project for staging. However, I already have a project for my mood tracker Pulselog. I could have created a new account for grammr to circumvent the limit, but I believe in engaging with free tier offerings like this in good faith. Gaming free tiers is the fastest way to get companies to stop offering them. Therefore, I’ve tried to carefully test on local, avoid large or long-lived deltas between staging and production and design migrations such that they would not cause issues as much as I could.
The Ugly: The Supabase database client is not great. There are a few things I do not like about it:
- It has its own custom query language. Try understanding the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
const {data, error} = await supabase
.from("flashcard")
.select(
`
*,
deck!inner (
id,
name,
user_id,
deck_study!inner (
user_id
)
)
`,
)
.eq("deck.deck_study.user_id", user.id);
Can you understand what’s going on here? Supabase performs JOINs via the ! operator and automatically infers JOIN columns. In this query, we select all fields from the flashcard table as well as selected fields from the deck and deck_study table. I really, really dislike this syntax: It is different from the SQL you’ve trained your brain to read for years; hiding the JOIN column might make sense for this custom language, but does not actually constitute a useful abstraction; and lastly, there are no type guarantees on the return values of this query. The code will have to continue as follows:
1
2
3
4
5
6
7
8
9
10
if (error) {
console.error("Failed to fetch flashcards:", error);
return NextResponse.json(
{error: "Failed to fetch flashcards"},
{status: 500},
);
}
// Parsing with zod
return NextResponse.json(FlashcardSchema.parse(data));
My real code is even more verbose, using safeParse and throwing with custom error messages. I tried writing an abstraction for this behavior, but this results in a magic utility function with various generics that I do not trust. Also, in order to maintain consistent usage of camelcase throughout your project, you’ll have to write a custom mapping that transforms data.user_id to userId. None of these problems are the end of the world in a vacuum, but they compound.
Drizzle ORM turned out to be a much more pleasant solution. Don’t get me wrong, it’s still an abstraction instead of raw SQL; but it’s much closer to other ORMs that I have worked with in the past than the client that Supabase offers. Consider this code:
1
2
3
4
5
6
7
8
9
10
11
12
13
const result = await db
.select({
flashcard: flashcards,
deck: {
id: decks.id,
name: decks.name,
userId: decks.userId,
},
})
.from(flashcards)
.innerJoin(decks, eq(flashcards.deckId, decks.id))
.where(and(...conditions))
.orderBy(desc(flashcards.updatedAt));
To be fair, this is slightly refactored code with one fewer JOIN, but I think it gets the point across. Is it extremely pretty? No, but I prefer it over what the Supabase client does. This code, in my opinion, is much more readable and requires less boilerplate than what the Supabase client forces you to write.
That said, I still think you can use the Supabase database client to quick-start a small project, but be prepared to migrate to a more mature solution eventually.
Outlook
I’ve enjoyed building this project. Even if it does not go anywhere, it is a very fun exercise in product thinking, in architecting and building, and I might end up building just for myself if nobody else wants to use it. There’s also a lot more interesting NLP work to be done: Relationships between words in a given sentence could be visualised to make linguistic agreement easier to understand. Using a combination of Regex and part-of-speech tagging, rules for words could be established: For instance, the fact that the word “пойти” is related to “идти”; the “по” prefix indicates that an action will take place in the future (so I understand). You can hopefully see how this could be useful to improve understanding of the language, and how a rule-based approach could be implemented to facilitate an extensible tagging mechanism.
If you’ve made it here, I still encourage you to check it out at grammr.app!